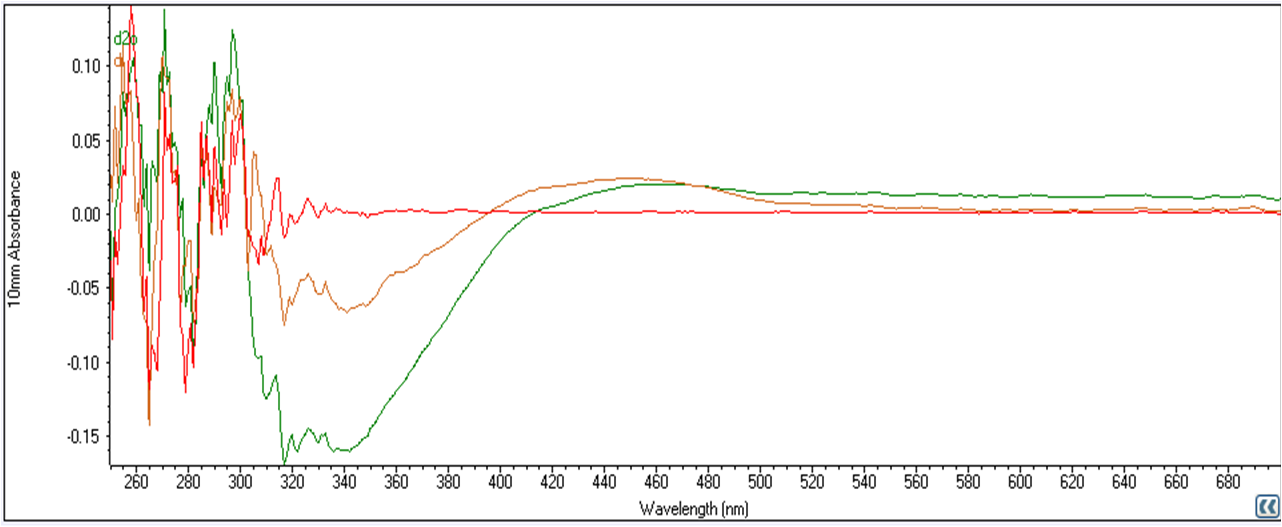
This post is written to supplement the P2PU Open Science Education Module, and in particular is meant to be an introduction to open research education.
My name is Anthony Salvagno and I’m an open notebook scientist. That basically means that I publish ALL of my research in real-time on the web. All of that research is attributed under a Creative Commons Attribution ShareAlike (CC BY-SA) license, so the information is free for anyone to use.
If the foundation of science is the pursuit of knowledge and to share that knowledge, then why is it acceptable for scientists to hide their research? Why is it ok for publishers to make you pay for that information? Why is it scientific culture to protect data like it is a commodity to be sold?
In truth, that system worked in the past because the technology was limited. Now the technology exists to instill a new culture. But what are the driving forces that would push someone to make this change? Simply put, I was fed up!
I was originally pushed into open science for one simple reason: my advisor was trained in an extremely closed system. In my first year of graduate school (and his lab), I was presented with the concept of open science, which then was barely taking hold. I was surprised to learn that scientific culture wasn’t a naturally open system, and in fact was surprisingly opposed to that concept.
Early in my graduate program, I became frustrated with the way scientific publications were written. I could only understand a small percentage of the articles I was reading, articles that were written by my peers. I knew most graduate students felt the same way. If we are producing the data and writing the papers, then why would we continue to perpetuate the cycle? So I decided that all of my research would be as accessible as possible.
At times, I would need to understand an experimental process, so I would scan the literature and try to repeat experiments to gain a foothold. I became frustrated with the content contained in the methods sections of scholarly work. Often, the methods would be vague, condensed, or just incomplete, and it would cost me time and money trying and failing to repeat experiments. So I began to document my protocols completely, including minor details that could potentially save other scientists a lot of time.
I have also come across scientific results of a questionable nature. Most of the time the results seemed incongruent with my own research, or even just based on my own expertise I knew there was no way to achieve those results. But the scientific process lacked transparency, so there was no way to understand how the researchers obtained their data. So I made sure that my analysis was entirely transparent, and I provide the data during every phase of analysis including the raw data.
In essence, I have become the scientist that I am because of the experiences that I’ve had. Instead of perpetuating the problems that exist in modern scholarly work, I work toward making a change.
I know I’m not the only scientist who has come across the same issues, in addition to other ones. There are a lot of open scientists who work toward the same goals. We hope to bring about a new culture to enhance the speed of science, to improve our collective knowledge, and to make discoveries that would be impossible in the old system. That is why open research practices are important to me, and that is why every scientist should be an open scientist.
Like this:
Like Loading...